SELECT
SELECT 문으로 특정 데이터를 추출하기
--▶ table의 모든 내용 출력
SELECT * FROM tab;
SELECT * FROM DEPARTMENTS;
SELECT * FROM EMPLOYEES;
--▶ calumn이름을 명시해서 특정 calumn만 보기
SELECT FIRST_NAME, LAST_NAME, SALARY , HIRE_DATE
FROM EMPLOYEES;
1. calumn이름에 별칭 지정
--1) AS (대문자로만 출력)
SELECT DEPARTMENT_ID as department_No, DEPARTMENT_NAME as DEPARTMENT_NAME
FROM DEPARTMENTS;
--2) " " (대소문자 구별)
SELECT DEPARTMENT_ID "department No",DEPARTMENT_NAME "department Name"
FROM DEPARTMENTS;
2. Concatenation : 여러 개의 coulmn과 문자열을 연결할 때 쓴다
: coulmn과 문자열 사이에 Concatenation연산자 " || " 로 연결하여 출력
--1) coulmn과 문자열 잇기
SELECT FIRST_NAME || '의 직급은' || JOB_ID || '입니다' AS 직급
FROM EMPLOYEES;
--2) 문자열 부분은 공백으로 남겨 coulmn만 잇기
SELECT FIRST_NAME ||' '|| LAST_NAME name,SALARY SALARY, HIRE_DATE HIRE_DATE
FROM EMPLOYEES;3. DISTINCT : 중복된 값을 한번만 표시되게 하기
SELECT DISTINCT JOB_ID
FROM EMPLOYEES;FROM
WHERE
▶ 조건 연산자
|
연산자
|
의미
|
|
=
|
같다.
|
|
>
|
보다 크다.
|
|
<
|
보다 작다.
|
|
>=
|
보다 크거나 같다.
|
|
<=
|
보다 작거나 같다
|
|
<>, !=, ^=
|
같지 않다.
|
| 연산자 | 의미 |
| AND | 여러 조건을 모두 만족해야 할 경우 AND 연산자를 사용한다. |
| OR | 두 가지 조건 중에서 한가지만 만족하더라도 검색할 수 있도록 하기 위해서는 OR연산자를 사용한다. |
| NOT | 반대되는 논리값을 구한다. |
| BETWEEN AND | 특정 범위 내에 속하는 데이터를 알아보려고 할 때 between A and B연산자를 사용 |
| IN | 동일한 칼럼이 여러 개의 값 중에 하나인지를 살펴보기 위해서 간단하게 표현할 수 있는 IN연산자를 사용한다. |
| LIKE | 검색하고자 하는 값을 정확히 모를 경우 와일드카드와 함께 사용하여 원하는 내용을 검색하는 연산자. |
| IS NULL | NULL이면 조건 충족 |
| IS NOT NULL | NULL이 아니면 조건 충족 |
| 와일드 카드 | 의미 |
| % | 문자가 없거나, 하나 이상의 문자가 어떤 값이 오든 상관없다. |
| _ | 하나의 문자가 어떤 값이 오든 상관없다. |
1. SELECT 문으로 특정 데이터를 추출하기
--▶ table의 모든 내용 출력
SELECT * FROM tab;
SELECT * FROM DEPARTMENTS;
SELECT * FROM EMPLOYEES;
--▶ calumn이름을 명시해서 특정 calumn만 보기
SELECT FIRST_NAME, LAST_NAME, SALARY , HIRE_DATE
FROM EMPLOYEES;
1. calumn이름에 별칭 지정
--1) AS (대문자로만 출력)
SELECT DEPARTMENT_ID as department_No, DEPARTMENT_NAME as DEPARTMENT_NAME
FROM DEPARTMENTS;
--2) " " (대소문자 구별)
SELECT DEPARTMENT_ID "department No",DEPARTMENT_NAME "department Name"
FROM DEPARTMENTS;
2. Concatenation : 여러 개의 coulmn과 문자열을 연결할 때 쓴다
: coulmn과 문자열 사이에 Concatenation연산자 " || " 로 연결하여 출력
--1) coulmn과 문자열 잇기
SELECT FIRST_NAME || '의 직급은' || JOB_ID || '입니다' AS 직급
FROM EMPLOYEES;
--2) 문자열 부분은 공백으로 남겨 coulmn만 잇기
SELECT FIRST_NAME ||' '|| LAST_NAME name,SALARY SALARY, HIRE_DATE HIRE_DATE
FROM EMPLOYEES;3. DISTINCT : 중복된 값을 한번만 표시되게 하기
SELECT DISTINCT JOB_ID
FROM EMPLOYEES;
2. WHEN 조건문으로 조건을 설정하기
1. 비교 연산자
--1) 급여 5천만원 미만 받는 직원의 사번과 성과 이름 급여 출력
SELECT EMPLOYEE_ID, FIRST_NAME, LAST_NAME, SALARY
FROM EMPLOYEES
WHERE SALARY<5000;
--2) 급여 7000만원 받는 직원의 직원의 사번과 성과 급여
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY
FROM EMPLOYEES
WHERE SALARY=7000;
--3) 부서번호 100번 인 직원에 관한 모든정보 출력
SELECT *
FROM EMPLOYEES
WHERE DEPARTMENT_ID=110;
2. 문자데이터 조회
: 문자 데이터는 반드시 단일 따옴표안에 표시, 대소문자 구분함
--1) 이름이 Lex인 사람과 사원번호와 급료를 출력하라
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY
FROM EMPLOYEES
WHERE FIRST_NAME='Lex';
--2) 이름이 John인 사람과 사원번호와 직원명과 부서 ID를 출력하라
SELECT EMPLOYEE_ID, FIRST_NAME, DEPARTMENT_ID
FROM EMPLOYEES
WHERE FIRST_NAME='John';
2-1. 날짜 데이터 조회
반드시 단일 따옴표 안에 표시한다. '년/월/일' 형식으로 기술한다.
--1) 2008년 이후에 입사한 직원
SELECT FIRST_NAME, HIRE_DATE
FROM EMPLOYEES
WHERE HIRE_DATE >= '2008/01/01';
3. 논리 연산자 AND / OR
--▶ AND 연산자 : 여러 조건을 모두 만족해야 할 경우
--1) 부서번호가 100번이고 직급이 FI_MGR인 직원
SELECT EMPLOYEE_ID,FIRST_NAME,PHONE_NUMBER,DEPARTMENT_ID,JOB_ID
FROM EMPLOYEES
WHERE DEPARTMENT_ID=100 and JOB_ID='FI_MGR';
--2) 급여가 5000원 이상에서 100000이하인 직원의 모든 정보 출력
SELECT *
FROM EMPLOYEES
WHERE SALARY>=5000 and SALARY<=10000;
--▶ OR 연산자 : 한 조건만 만족해도 될 경우
--1) 부서번호가 100번이거나 직급이 FI_MGR인 직원
SELECT EMPLOYEE_ID,FIRST_NAME,PHONE_NUMBER,DEPARTMENT_ID,JOB_ID
FROM EMPLOYEES
WHERE DEPARTMENT_ID=100 or JOB_ID='fi_mgr';
--2) 사원번호가 134이거나 201이거나 107인 직원의 모든 정보 출력
SELECT *
FROM EMPLOYEES
WHERE EMPLOYEE_ID=134 or EMPLOYEE_ID=201 or EMPLOYEE_ID=107;
4. 부정 연산자 NOT
: 반대되는 논리값을 구한다
--1) 부서번호가 100번이 아닌 직원
SELECT EMPLOYEE_ID,FIRST_NAME,PHONE_NUMBER,DEPARTMENT_ID,JOB_ID
FROM EMPLOYEES
WHERE not DEPARTMENT_ID=100;
5. between A and B 연산자
: 특정 범위 내에 속하는 데이터를 알아보려고 할 때 between A and B연산자를 사용
--1) 급여가 2500에서부터 4500까지의 범위에 속한 사원
SELECT EMPLOYEE_ID,FIRST_NAME,SALARY
FROM EMPLOYEES
WHERE SALARY between 2500 and 4500;
-- = WHERE SALARY>= 2500 and SALARY<=4500;
--2) 급여가 2000에서부터 3000까지의 범위에 속한 사원
SELECT EMPLOYEE_ID,FIRST_NAME,SALARY
FROM EMPLOYEES
WHERE SALARY between 2000 and 3000;
6. IN 연산자
: 동일한 칼럼이 여러 개의 값중에 하나를 살펴보기 위해서 IN연산자를 사용한다
--1) 직원 번호가 177이거나101이거나184인 사원
SELECT EMPLOYEE_ID,FIRST_NAME,SALARY
FROM EMPLOYEES
WHERE EMPLOYEE_ID in(177,101,184);
--WHERE EMPLOYEE_ID=177 OR EMPLOYEE_ID=101 OR EMPLOYEE_ID=184;
--2) 부서번호가 10,20,30, 중 하나에 소속된 직원번호,이름,급여 출력 in / or 둘다 사용
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY,DEPARTMENT_ID
FROM EMPLOYEES
WHERE DEPARTMENT_ID in(10,20) or DEPARTMENT_ID=30;
--3) 사원테이블에서 JOB_ID가 'SA_MAN' , 'ST_MAN' , 'PU_MAN' , 'AC_MGR' 인 사원번호, 사원명, 직무번호를 출력하라
SELECT EMPLOYEE_ID,FIRST_NAME,DEPARTMENT_ID,JOB_ID,DEPARTMENT_NAME
FROM EMPLOYEES
WHERE JOB_ID in('SA_MAN' , 'ST_MAN' , 'PU_MAN' , 'AC_MGR');
7. LIKE 연산자
: 동일한 칼럼이 여러 개의 값중에 하나를 살펴보기 위해서 IN연산자를 사용한다
| 와일드 카드 | 의미 |
| % | 문자가 없거나, 하나 이상의 문자가 어떤 값이 오든 상관없다. |
| _ | 하나의 문자가 어떤 값이 오든 상관없다. |
7-1) 와일드카드 %
: %는 검색하고자 하는 값을 정확히 모를 경우 사용한다. %는 몇 개의 문자가 오든 상관없다는 의미다.
--1) K로 시작하는 사원
SELECT EMPLOYEE_ID, FIRST_NAME
FROM EMPLOYEES
WHERE FIRST_NAME LIKE 'K%';
--2) 이름중에 k를 포함하는 사원
SELECT EMPLOYEE_ID,FIRST_NAME
FROM EMPLOYEES
WHERE Lower (FIRST_NAME) LIKE '%k%';
--3) 이름중이 k로 끝나는 사원
SELECT EMPLOYEE_ID, FIRST_NAME
FROM EMPLOYEES
WHERE FIRST_NAME LIKE '%k';
--(4) 이름에 k를 포함하지 않는 사원
SELECT EMPLOYEE_ID,FIRST_NAME
FROM EMPLOYEES
WHERE lower(FIRST_NAME) not like '%k%';7-2) 와일드카드 _
: _는 한 문자를 대신해서 사용하는 것
--(1) 이름이 5글자이되 세번째 글자가 s인 사원
SELECT EMPLOYEE_ID, FIRST_NAME
FROM EMPLOYEES
WHERE FIRST_NAME LIKE '__s__';| 조건 | 설명 | 조건에 맞는 문자 |
| LIKE _A | 문자가 2글자이며 두 번째 글자가 A로 끝남 | AA, BA, CA |
| LIKE _A% | 문자의 두번째 글자가 A여야함 | AAA, BAA, CA213S |
| LIKE A__ | 문자가 3글자이며 A로 시작 | AAA, ABC, ABF |
| LIKE _a__ | 문자가 4글자이며 2번째 글자는 a여야함 | AaVC, Ba12 |
3. 와일드카드(% 와 _)를 조합해서 사용
--(1) 이름의 두 번째 글자가 d인 사원
SELECT EMPLOYEE_ID, FIRST_NAME
FROM EMPLOYEES
WHERE FIRST_NAME LIKE '_d%';
8. NULL을 위한 연산자 ( IS NULL / IS NOT NULL )
• 오라클에서는 칼럼에 NULL값이 저장되는 것을 허용한다
• NULL은 미확정, 알 수 없는(unkown)을 의미한다 숫자 0도 빈공간도 아니고 어떤 값이 존재하기는 하지만 어떤 값인지는 알 수 섮다는 것을 의미한다.
• 그러므로 NULL는 연산자로 판단 할 수 없다 그리고 연산, 할당, 비교가 불가능하다.
ex) 100+NULL=NULL
| is null | NULL이면 조건 충족 |
| is not null | NULL이 아니면 조건 충족 |
8-1) A is null : A를 제외한 결과 출력
--1) 커미션을 받지 않는 사원
SELECT EMPLOYEE_ID, FIRST_NAME, COMMISSION_PCT, JOB_ID
FROM EMPLOYEES
WHERE COMMISSION_PCT is null;
--2) 자신의 직속상관이 없는 직원의 전체 이름과 직원번호, 업무ID를 출력하라
SELECT FIRST_NAME,LAST_NAME,EMPLOYEE_ID, JOB_ID,MANAGER_ID
FROM EMPLOYEES
WHERE MANAGER_ID is null;
8-2) A is not null : A를 포함하는 결과 출력
--1) 커미션을 받는 사원
SELECT EMPLOYEE_ID, FIRST_NAME, COMMISSION_PCT, JOB_ID
FROM EMPLOYEES
WHERE COMMISSION_PCT is not null;
--2) 커미션을 받는 사원만 출력하되 사원번호,이름,급여,수당율,수당금액을 출력하라
-- SELECT에서 계산도 가능
SELECT EMPLOYEE_ID,FIRST_NAME,SALARY,COMMISSION_PCT,(SALARY*COMMISSION_PCT)
FROM EMPLOYEES
WHERE COMMISSION_PCT is not null;GROUP BY
▶ GROUP BY 절
|
SELECT 칼럼명, 그룹함수(컬럼명)
FROM 테이블명
WHERE 조건문
GROUP BY 칼럼명
|
- GROUP BY 절은 그룹 함수와 함께 사용하며 특정 조건으로 데이터들을 묶을 수 있다.
- WHERE절뒤에, ORDER BY절 보단 앞에 GROUP BY 절을 추가한다.
- 나누고자 하는 그룹의 컬럼명은 SELECT절과 GROUP BY절 뒤에 추가한다.
- SELECT절에 있는 그룹함수를 제외한 모든 컬럼과 표현식은 GROUP BY 절에 명시해야 한다.
- 그룹함수와 함께 사용되는 상수는 GROUP BY 절에 추가하지 않아도 된다.
: 부서번호를 기준으로 부서번호를 묶어 오름차순대로 출력한다 (묶었으니 부서번호가 중복없이 출력된다)
SELECT DEPARTMENT_ID
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
ORDER BY DEPARTMENT_ID;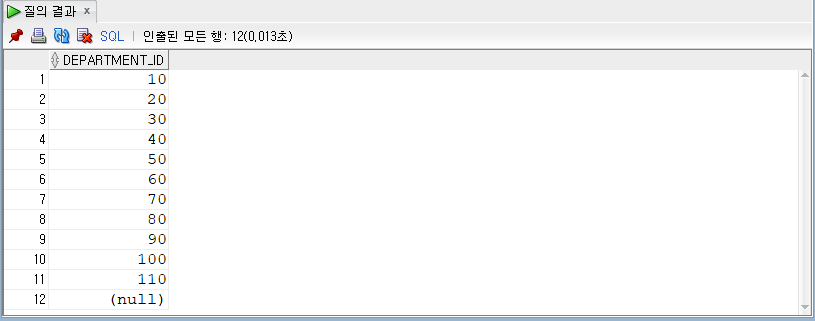
: 부서별 최대 급여와 최소 급여 구하기
SELECT DEPARTMENT_ID, MAX(SALARY) "최대 급여", MIN(SALARY) "최소 급여"
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
ORDER BY DEPARTMENT_ID;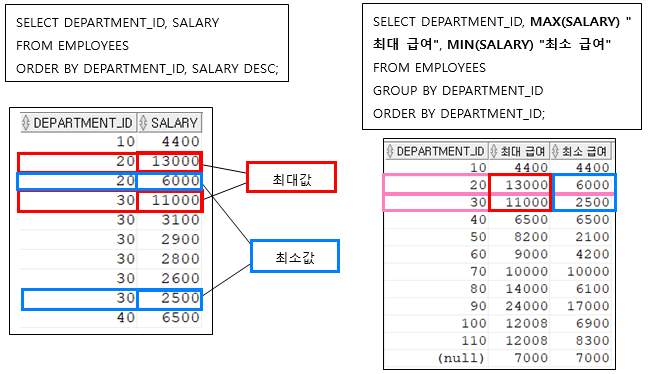
: 소속 부서별 급여의 합과 급여의 평균 구하기
SELECT DEPARTMENT_ID, SUM(SALARY), AVG(SALARY)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
ORDER BY DEPARTMENT_ID;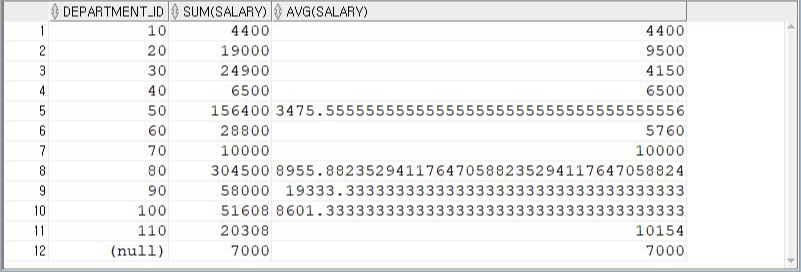
HAVING
▶ HAVING 그룹함수의 조건절
- SELECT 절에 조건을 사용하여 결과를 제한할 때는 WHERE 절을 사용하지만
그룹의 결과를 제한할때는 HAVING절을 사용한다. - GROUP BY절 다음에 위치해 GROUP BY한 결과를 대상으로 다시 필터를 거는 역할
- HAVING 다음에는 SELECT 리스트에 사용했던 집계함수를 이용한 조건을 명시
SELECT DEPARTMENT_ID, AVG(SALARY)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
HAVING AVG(SALARY) > 5000
ORDER BY DEPARTMENT_ID;
: 부서의 아이디 그룹 기준으로 최대 급여(5000원 보다 높아야 한다)와 최소 급여를 출력하기
SELECT DEPARTMENT_ID, MAX(SALARY), MIN(SALARY)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
HAVING MAX(SALARY) > 5000
ORDER BY DEPARTMENT_ID;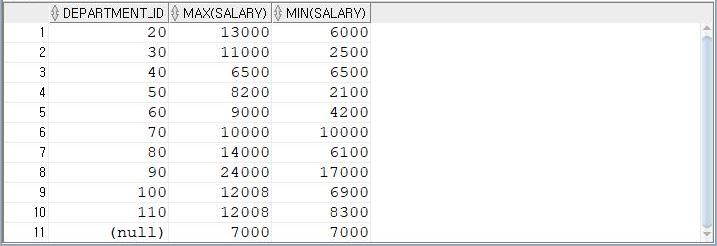
ORDER BY 컬럼명/별칭/컬럼순서 [ASC]/[DSC]
정렬을 위한 Order By 절
| Order By | ASC | 오름차순으로 정렬 (기본 디폴트값) 오라클에서는 자바처럼0번째부터 시작안하고 1번째부터 시작한다 생략 가능 |
| DESC | 내림차순으로 정렬 |
9-1) 사원 번호를 기준으로 오름차순으로 정렬
SELECT EMPLOYEE_ID,FIRST_NAME
FROM EMPLOYEES
order by EMPLOYEE_ID ASC;9-2) 사원번호를 기준으로 내림차순으로 정렬
SELECT EMPLOYEE_ID, FIRST_NAME
FROM EMPLOYEES
ORDER BY EMPLOYEE_ID DESC;'DB > SQL' 카테고리의 다른 글
| Oracle SQL DB 계정 생성 (0) | 2022.11.02 |
|---|---|
| Oracle 함수 모음 (0) | 2022.04.11 |
| 집합 연산자 (0) | 2022.04.10 |
| PreparedStatement (0) | 2022.04.06 |
| PL / SQL (0) | 2022.04.03 |