|
그룹 함수 : 하나 이상의 행을 그룹으로 묶어 연산하여 총합, 평균 등 하나의 결과로 나타난다
|
※ 컬럼과 그룹 함수를 같이 사용할 때 유의할 점
SELECT FIRST_NAME, MIN(SALARY) FROM EMPLOYEES;

즉 SELECT 문에 그룹 함수를 사용하는 경우 그룹 함수를 적용하지 않은 단순 칼럼은 올 수 없다.
▶ GROUP BY 절
|
SELECT 칼럼명, 그룹함수(컬럼명)
FROM 테이블명
WHERE 조건문
GROUP BY 칼럼명
|
- GROUP BY 절은 그룹 함수와 함께 사용하며 특정 조건으로 데이터들을 묶을 수 있다.
- WHERE절뒤에, ORDER BY절 보단 앞에 GROUP BY 절을 추가한다.
- 나누고자 하는 그룹의 컬럼명은 SELECT절과 GROUP BY절 뒤에 추가한다.
- SELECT절에 있는 그룹함수를 제외한 모든 컬럼과 표현식은 GROUP BY 절에 명시해야 한다.
- 그룹함수와 함께 사용되는 상수는 GROUP BY 절에 추가하지 않아도 된다.
: 부서번호를 기준으로 부서번호를 묶어 오름차순대로 출력한다 (묶었으니 부서번호가 중복없이 출력된다)
SELECT DEPARTMENT_ID FROM EMPLOYEES GROUP BY DEPARTMENT_ID ORDER BY DEPARTMENT_ID;
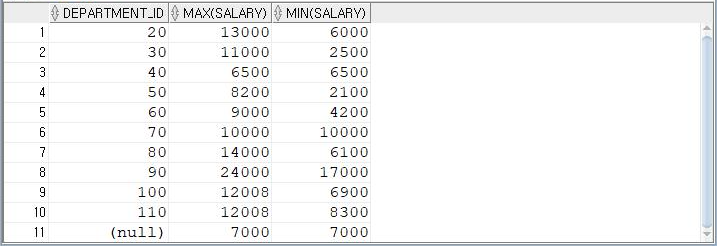
: 부서별 최대 급여와 최소 급여 구하기
SELECT DEPARTMENT_ID, MAX(SALARY) "최대 급여", MIN(SALARY) "최소 급여" FROM EMPLOYEES GROUP BY DEPARTMENT_ID ORDER BY DEPARTMENT_ID;
: 소속 부서별 급여의 합과 급여의 평균 구하기
SELECT DEPARTMENT_ID, SUM(SALARY), AVG(SALARY) FROM EMPLOYEES GROUP BY DEPARTMENT_ID ORDER BY DEPARTMENT_ID;
▶ HAVING 그룹함수의 조건절
- SELECT 절에 조건을 사용하여 결과를 제한할 때는 WHERE 절을 사용하지만
그룹의 결과를 제한할때는 HAVING절을 사용한다. - GROUP BY절 다음에 위치해 GROUP BY한 결과를 대상으로 다시 필터를 거는 역할
- HAVING 다음에는 SELECT 리스트에 사용했던 집계함수를 이용한 조건을 명시
SELECT DEPARTMENT_ID, AVG(SALARY) FROM EMPLOYEES GROUP BY DEPARTMENT_ID HAVING AVG(SALARY) > 5000 ORDER BY DEPARTMENT_ID;
: 부서의 아이디 그룹 기준으로 최대 급여(5000원 보다 높아야 한다)와 최소 급여를 출력하기
SELECT DEPARTMENT_ID, MAX(SALARY), MIN(SALARY) FROM EMPLOYEES GROUP BY DEPARTMENT_ID HAVING MAX(SALARY) > 5000 ORDER BY DEPARTMENT_ID;
⦁ SUM : 그룹의 누적 합계를 반환하는 함수
: 직원의 총 급여 구하기
SELECT SUM(SALARY) FROM EMPLOYEES;
|
SUM
|
그룹의 누적 합계를 반환한다.
|
: 직원의 총 급여 구하기
SELECT SUM(SALARY) FROM EMPLOYEES;
|
AVG
|
그룹의 평균을 반환한다.
|
: 직원의 평균 급여 구하기
SELECT AVG(SALARY) FROM EMPLOYEES;
|
COUNT
|
그룹의 총 개수를 반환한다.
|
그룹함수는 다른 연산자와는 달리, 해당 컬럼값이 NULL인 것을 제외하고 계산하기 때문에 결과를 NULL로 반환하지 않는다. 그래서 로우(레코드) 개수 구하는 COUNT 함수는 NULL 값에 대해서는 세지 않는다.
: 전체 사원의 수와 커미션을 받는 사원의 수
SELECT COUNT(*) AS "전체 사원 수" , COUNT(COMMISSION_PCT) AS "커미션 받는 사원 수" FROM EMPLOYEES;
|
MAX / MIN
|
그룹의 최댓값 / 최솟값을 반환한다.
|
: 최근에 입사한 사원과 가장 오래전에 입사한 직원의 입사일 출력하기
SELECT TO_CHAR(MAX(HIRE_DATE), 'YYYY-MM-DD'), TO_CHAR(MIN(HIRE_DATE), 'YYYY-MM-DD') FROM EMPLOYEES;

| ROLLUP | 각 기준별 소계를 요약하는 함수 |
ROLLUP()에 지정된 컬럼들은 소계(전체가 아닌 어느 한 부분만을 셈한 합계)의 기준이 되는 컬럼들이다.
- GROUP BY 절과 같이 사용되며 GROUP BY절에 의해 그룹 지어진 집합결과에 대해서 좀 더 상세한 정보를 반환하는 기능을 수행한다
- GROUP BY 절에서 ROLLUP (coulmn1, coulmn2, ...) 사용됨
- ROLLUP(coulmn)로 명시한 표현식을 기준으로 집계한 결과, 추가 정보 집계
- ROLLUP(coulmn)로 명시한 표현식 수와 순서에 따라 레벨 별로 집계
직업별로 급여 합계와 총계를 구해보자
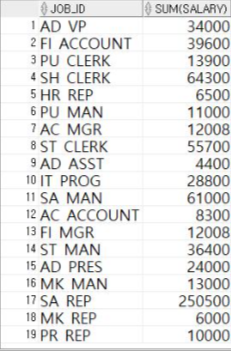
① 먼저 GROUP BY를 사용해서 직업별로 급여 합계를 구하는 예제를 만든다
SELECT JOB_ID, SUM(SALARY) FROM EMPLOYEES GROUP BY JOB_ID;
② GROUP BY뒤에 ROLLUP을 사용해서 직업별로 급여 합계와 총계를 출력한다
SELECT JOB_ID, SUM(SALARY) FROM EMPLOYEES GROUP BY ROLLUP(JOB_ID);
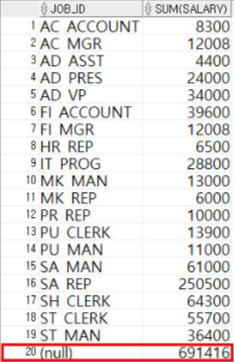
--> 급여 합계에 대한 총계가 추가 되었다.
- ROLLUP 예제
① 부서와 직무별 급여의 합 및 사원수와
② 부서별 급여의 합과 사원수,
③ 전체 사원의 급여의 합과 사원수를 구하세요.
: 부서ID가 바뀔때마다 부서별 집계가 출력되고 모든 부서가 출력되면 전체 집계정보가 출력된다.
SELECT DEPARTMENT_ID, JOB_ID, COUNT(*), SUM(SALARY) FROM EMPLOYEES GROUP BY ROLLUP(DEPARTMENT_ID, JOB_ID) ORDER BY DEPARTMENT_ID;
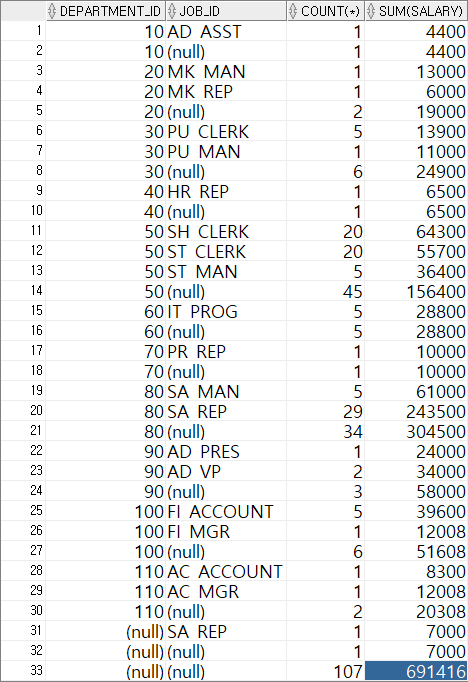
각 부서ID(NULL도 포함) 총합 107개 > 사원수 107명
전체 사원의 급여의 합 > 691416
|
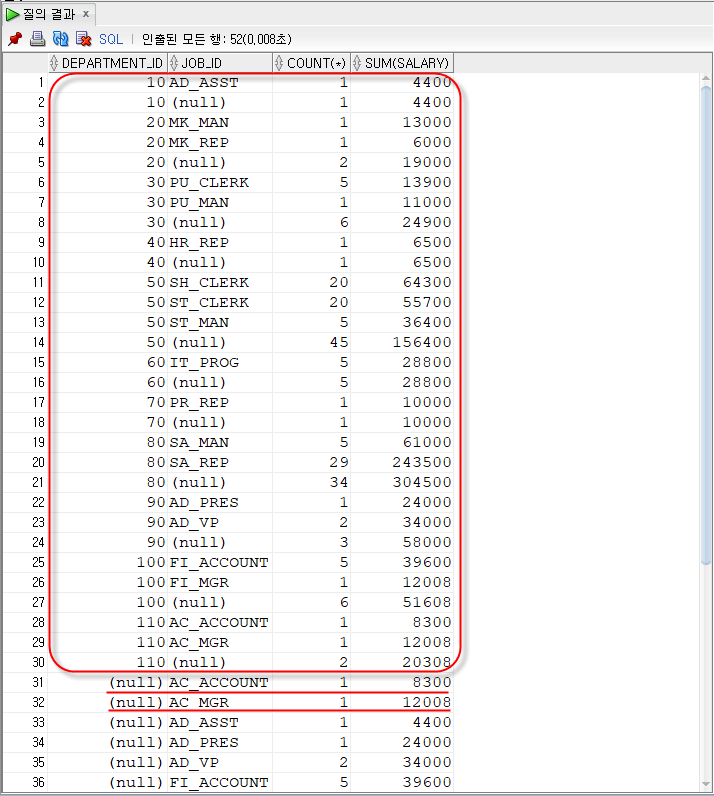
CUBE
|
소계와 전체 합계까지 출력하는 함수 |
CUBE()는 명시한 표현식 개수에 따라 가능한 모든 조합별로 집계한 결과를 반환한다.
SELECT DEPARTMENT_ID, JOB_ID, COUNT(*), SUM(SALARY) FROM EMPLOYEES GROUP BY CUBE(DEPARTMENT_ID, JOB_ID);
| 단일행 함수 : 행 마다 함수가 적용되어 결과를 반환한다. |
|
문자 함수
|
문자열을 다른 형태로 변환하여 나타낸다.
|
| UPPER / LOWER / INITCAT | 대문자로 변환 / 소문자로 변환 / 첫글자는 대문자 나머지 글자는 소문자로 변환 |
|
CONCAT
|
문자의 값을 연결한다
|
|
SUBSTR / SUBSTRB
|
문자를 찰라 추출한다 (한글 1Byte / 2Byte)
|
|
LENGTH / LENGTHB
|
문자를 길이로 반환한다 (한글 1Byte / 2Byte)
|
|
INSTR / INSTRB
|
특정 문자의 위치 값을 반환한다 (한글 1Byte / 2Byte)
|
|
LPAD / RPAD
|
입력 받은 문자열과 기호를 정렬하여 특정 길이의 문자열로 반환한다
|
|
TRIM
|
잘라내고 남은 문자를 표시한다
|
|
CONVERT
|
CHAR SET을 변환한다
|
|
CHR / ASCII
|
ASCII 코드 값을 변환한다 / ASII 코드값을 문자로 변환한다
|
|
REPLACE
|
문자열에서 특정 문자를 변경한다
|
|
숫자 함수
|
숫자 값을 다른 형태로 변환하여 나타낸다.
|
| ABS |
절대값을 반환한다
|
|
COS
|
CONSINE 값을 반환한다
|
|
CEIL / FLOOR
|
소수점 아래를 올린다 / 소수점 아래를 잘라낸다
|
|
LOG
|
LOG값을 반환한다 |
|
POWER
|
POWER(m,n) m의 n승을 반환한다 |
|
SIGN
|
SIGN값을 반환한다 |
|
SIN
|
SINE값을 반환한다 |
|
TAN
|
TANGENT값을 반환한다 |
|
ROUND
|
특정 자릿수에서 반올림한다
|
|
TRUNC
|
특정 자릿수에서 잘라낸다 (버림)
|
|
MOD
|
입력 받은 수를 나눈 나머지 값을 반환한다
|
|
날짜 함수
|
날짜 값을 다른 형태로 변환하여 나타낸다.
|
|
SYSDATE
|
시스템에 저장된 날짜를 반환한다
|
|
MONTHS_BETWEEN
|
두 날짜 사이가 몇개월인지 반환한다
|
|
ADD_MONTH
|
특정 날짜에 개월 수를 더한다
|
|
NEXT_DAY
|
특정 날짜에서 최초로 도래하는 인자로 받은 요일의 날짜를 반환한다 |
|
LAST_DAY
|
해당 달의 마지막 날짜를 반환한다
|
|
ROUND
|
인자로 받은 날짜를 특정 기준으로 반올림한다
|
|
TRUNC
|
인자로 받은 날짜를 특정 기준으로 버림한다
|
|
변환 함수
|
문자, 날짜, 숫자 값을 서로 다른 타입으로 변환하여 나타낸다.
|
| TO_CHAR |
날짜형 혹은 숫자형을 문자형으로 변환
|
|
TO_DATE
|
문자형을 날짜형으로 변환
|
|
TO_NUMBER
|
문자형을 숫자형으로 변환
|
|
일반 함수
|
기타 함수
|
| NVL |
첫 번째 인자로 받은 값이 NULL과 같으면 두번째 인자 값으로 변경
|
|
DECODE
|
첫 번째 인자로 받은 값을 조건에 맞춰 변경 (if와 유사)
|
|
CASE
|
조건에 맞는 문장을 수행한다 (switch와 유사)
|
'DB > SQL' 카테고리의 다른 글
| Oracle SQL DB 계정 생성 (0) | 2022.11.02 |
|---|---|
| SELECT문 절 / 연산자 (0) | 2022.04.11 |
| 집합 연산자 (0) | 2022.04.10 |
| PreparedStatement (0) | 2022.04.06 |
| PL / SQL (0) | 2022.04.03 |